

By Dishani Sen
Welcome again, data enthusiasts!
In the age of big data, data quality and governance are crucial aspects for any organisation seeking to extract meaningful insights from their data. Data governance refers to everything you do to keep data safe, private, accurate, accessible, and usable. It encompasses the activities that people must perform, the protocols that they must adhere to, and the technology that supports them throughout the data life cycle.

In this blog, at first we talk about Google Cloud Data Catalog (it is now a part of Dataplex). We will first delve deep into Google Cloud Data Catalog, then introduce Dataplex. We also present a comparison for lucid understanding. Finally, we throw some light on the unification of these two GCP services.
Leveraging Google Cloud Data Catalog for Metadata Management:
Effective metadata management enhances data discoverability and promotes data understanding. It is a critical component of any data-driven organisation as it enhances data discoverability and promotes data understanding. In this blog, we will explore how to leverage Google Cloud Data Catalog to create and manage metadata entries, apply tags, and establish data lineage, thereby optimising the management of your data assets.

What is Google Cloud Data Catalog?
Google Cloud Data Catalog is a fully managed metadata management service that allows organisations to discover, manage, and understand their data assets on Google Cloud Platform (GCP). It acts as a central repository for storing metadata information about data objects such as tables, datasets, views, pipelines, and more. By organising and categorising metadata, Data Catalog makes it easier for users to find and utilize the right data for their tasks.
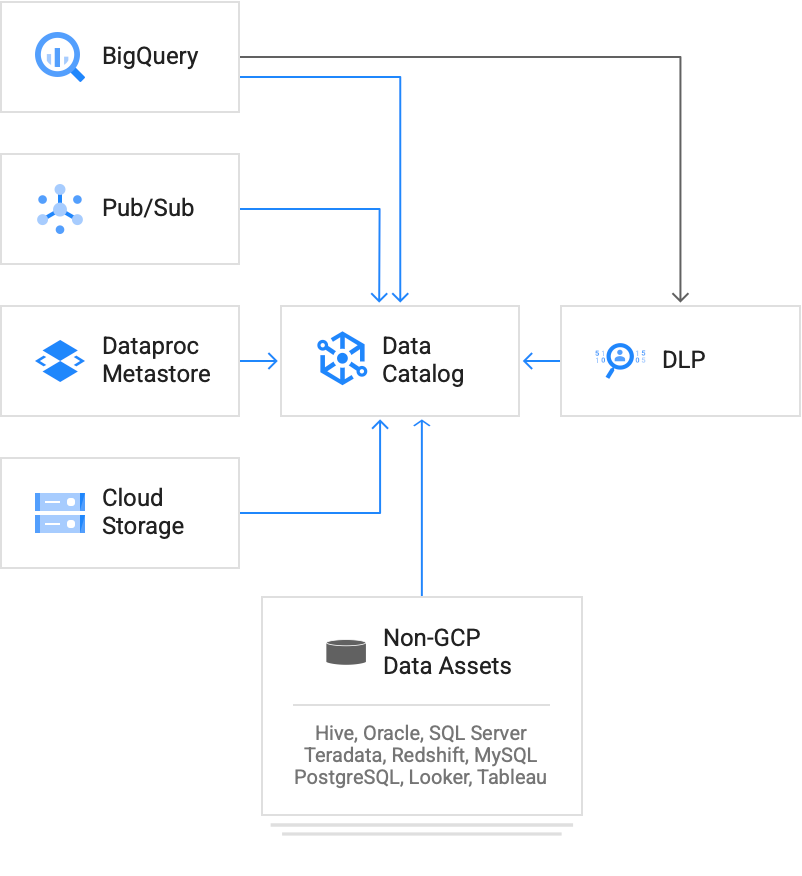
Creating and Managing Metadata Entries
Data Catalog allows users to create metadata entries for various data assets present in their GCP environment. Metadata entries provide descriptive information about the data, making it easier for users to comprehend its contents and usage. To create a metadata entry, follow these steps:
- Identify Data Assets: Start by identifying the data assets that require metadata management. These could be datasets in BigQuery, data files in Google Cloud Storage, or even data pipelines in Cloud Data Fusion.
- Catalog the Metadata: Using the Data Catalog API or the Google Cloud Console, create metadata entries for each data asset. Include relevant information such as data schema, data source, data owner, and any other relevant attributes that facilitate data discovery and understanding.
- Add Descriptive Tags: Data Catalog allows you to add custom tags to metadata entries. Tags help in categorising and organising data assets based on different criteria such as data sensitivity, department ownership, or data quality.
Establishing Data Lineage
Data lineage provides a comprehensive record of data flow from its source to various destinations throughout its lifecycle. It is crucial for auditing, data governance, and ensuring data quality. Google Cloud offers several services that can help establish data lineage:
- Cloud Data Fusion: Cloud Data Fusion is a fully managed data integration service that enables the creation of data pipelines. By building data pipelines in Data Fusion, you can visually track the flow of data from source systems to target systems, thereby establishing data lineage.
- Apache Atlas: Apache Atlas, though not a Google Cloud service, can be integrated with GCP to provide advanced data governance capabilities. It allows you to track data movement and metadata changes across multiple platforms and services, enabling a more comprehensive data lineage view.
Implementing Data Quality Monitoring
Data quality monitoring is essential to ensure that data remains accurate, consistent, and reliable over time. Google Cloud offers powerful tools for setting up data quality checks:
- Google Cloud Monitoring: Google Cloud Monitoring allows you to define custom monitoring metrics and alerts based on data quality rules. By setting up monitoring for specific data attributes or thresholds, you can receive real-time alerts when data anomalies or discrepancies occur.
- BigQuery Data Quality Checks: Within BigQuery, you can implement automated data quality checks using SQL queries. These checks can range from simple data type validations to complex integrity constraints, ensuring the quality and validity of the data stored in BigQuery tables.
Complying with Data Governance Regulations
Data governance regulations, such as GDPR, CCPA, and HIPAA, require organisations to protect data privacy, maintain compliance, and implement appropriate security measures. Google Cloud provides several features to help achieve compliance:
- Data Encryption: Google Cloud offers encryption at rest and in transit for data stored and transmitted through its services. Utilize Google Cloud Key Management Service (KMS) to manage encryption keys and ensure data remains secure.
- Access Controls: Implement fine-grained access controls using Google Cloud Identity and Access Management (IAM) to limit data access to authorised users only. Enforce the principle of least privilege to minimise the risk of data breaches.
- Auditing and Monitoring: Enable auditing and monitoring features in Google Cloud to track data access and modifications. Google Cloud's Audit Logs and Cloud Logging help maintain an audit trail for compliance purposes.
Data Retention and Deletion Policies
Proper data retention and deletion policies are crucial for managing data storage costs, meeting compliance requirements, and reducing data privacy risks. Google Cloud provides tools for implementing such policies:
- Google Cloud Storage Lifecycle Policies: With Google Cloud Storage, you can define lifecycle policies to automatically transition data to different storage classes based on its age. This allows you to store critical data in high-performance storage and move less frequently accessed data to more cost-effective storage tiers.
- BigQuery Data Expiration: In BigQuery, you can set up data expiration policies to automatically delete data older than a specified duration. This ensures that data no longer needed is removed, reducing storage costs and adhering to data retention regulations.
Conclusion:
Data quality and governance are critical components of a successful data strategy in Google Cloud. By mastering the techniques covered in this guide, data and ML engineers can ensure the accuracy, reliability, and compliance of their data pipelines. From data validation and cleaning to metadata management and compliance considerations, each topic plays a crucial role in maintaining trustworthy and valuable data assets. By adhering to best practices and leveraging Google Cloud's powerful services, you can establish a robust data quality and governance framework, empowering your organisation to make data-driven decisions with confidence and precision.
What is Dataplex?
Google Cloud Dataplex is a new data management and governance platform offered by Google Cloud. Dataplex aims to help organisations get control over their complex data environments. Dataplex provides a unified interface to manage data across data lakes, data warehouses, and other storage systems. It aims to simplify and optimise the process of ingesting, preparing, and managing data for analytics and machine learning workloads across multi-cloud and hybrid environments. Dataplex utilises an intelligent metadata fabric to connect disparate data silos and tools. This fabric coordinates collaboration and data management workflows.
Key architectural components:
Data catalog - Indexes metadata from data sources via automatically created Apache Atlas entries.
Data lakes - Provides a scalable, secure and unified data lake built on Cloud Storage or BigQuery.
Analytics engines - Integrates platforms like BigQuery for analysis.
Orchestration services - Apache Spark and Apache Airflow for pipeline execution.
Partner data services - Leverage 3rd party capabilities like data quality solutions.
Dataplex is serverless, meaning resources scale automatically as needed. Usage-based pricing means paying only for consumed resources.
Functionality
- Data Integration and Preparation: Dataplex provides capabilities for ingesting data from various sources, preparing and transforming the data, and loading it into target destinations such as BigQuery or Cloud Storage.
- Data Fabric: Dataplex creates a unified data fabric that spans across multiple cloud providers and on-premises environments. It allows users to access and manage data from different sources in a consistent manner, abstracting the complexities of data integration.
- Metadata Management: Dataplex incorporates a robust metadata management system that helps track and organise data assets, data lineage, data quality, and other metadata information. This allows users to gain deeper insights into their data and ensure data governance.
Use Cases
Dataplex is designed for enterprises dealing with large volumes of data from various sources across multiple cloud platforms and on-premises. It simplifies data integration and preparation processes while providing a unified view of the data fabric.
In a data-driven world, organisations strive to make data easily discoverable, accessible, and secure, enabling teams to rely on data for actionable business outcomes. However, many struggle to achieve this vision due to data underutilisation, unreliable data sources, and inadequate governance practices. But fret not! Dataplex is here to change the game (that's what Google claims!)
The Challenge: Why Dataplex?
Accenture's study revealed that two-thirds of a company's data goes unused for analytics, while unreliable data sources slow down the work of 90% of the surveyed teams. Gartner predicts that organisations may fail to scale digital businesses if they don't adopt modern data and analytics governance approaches. The answer lies in comprehensive data governance solutions, and that's where Dataplex comes in.
Dataplex: The Unified Data Fabric
Dataplex was introduced to provide customers with a unified data fabric, empowering them to manage and govern distributed data at scale. Dataplex revolves around the core principles of governance based on business context and business logic, enabling you to define governance rules based on data attributes, not just physical storage. It also offers an open and extensible platform for end-to-end data governance across your entire data landscape.
Building the Pillars of Governance
To achieve effective governance, Dataplex focuses on three key pillars: Discover, Secure, and Trust.
- Discover Data with Business Context: Dataplex empowers you to centrally manage metadata in a data catalog. Enrich your technical metadata with relevant business context through stack templates. Dataplex introduced two new capabilities for better business enrichment: a Business Glossary for standardised business terms and Rich Text Documentation for shared understanding of data.
- Centrally Secure and Manage Your Data: Define Access Control policies based on business attributes, logically organise data by data domains and sub-domains, and map these policies to underlying physical resources. With Dataplex, you can enable distributed ownership of data while maintaining centralised governance.
- Build Trust in Your Data: Automate data profiling and data quality checks. Profile your data and auto-generate data quality rules to ensure completeness, accuracy, validity, and freshness. Monitor data quality metrics with built-in dashboards, reports, and the ability to quarantine data that doesn't meet your data quality thresholds.
Data Lineage
Dataplex introduced end-to-end data lineage where you can easily trace your data's origins and relationships, understand your data better, and use lineage as a foundation for applying governance and compliance policies. Dataplex offers lineage support for BigQuery, Composer, and Data Fusion, enabling you to track data movement pipelines and analytics stores.
Key Differences between Google Cloud Data Catalog and Dataplex
- Focus and Purpose: The primary focus of Google Cloud Data Catalog is on metadata management and data asset discovery within the Google Cloud ecosystem. On the other hand, Dataplex is more geared towards data integration, preparation, and creating a unified data fabric across multi-cloud and hybrid environments.
- Scope of Integration: Data Catalog mainly integrates with Google Cloud services like BigQuery, Cloud Storage, Cloud Data Fusion, and Apache Atlas for data lineage. Dataplex, however, is designed to integrate with various cloud providers and on-premises data sources, enabling cross-platform data management.
- Complexity and Scale: Data Catalog is suitable for organisations that primarily use Google Cloud Platform and require basic metadata management and data lineage features. Dataplex is targeted at enterprises dealing with complex data integration scenarios, large-scale data volumes, and multiple data sources.
- Data Fabric: The concept of a unified data fabric is unique to Dataplex. It allows users to access and manage data from different sources consistently, making it a powerful solution for data integration and analytics in multi-cloud and hybrid environments.
The Unification: Data Catalog is a part of Dataplex
Google Cloud Data Catalog and Dataplex have joined forces to provide a unified and seamless user experience. With this unification, customers gain access to an integrated metadata platform that bridges the gap between technical and business metadata, enabling intelligent data management and governance like never before.
Unification for a Coherent User Experience
Prior to this unification, data owners, stewards, and governors had to juggle between two different interfaces - Dataplex for organising and managing data and Data Catalog for data discovery, understanding, and enrichment.
Now, with this unified experience, Google offer a seamless solution where customers can:
- Discover and Catalog Data: Automatically discover and catalog all the data owned by the organisation, creating a comprehensive repository for metadata.
- Understand Data Lineage: Trace data lineage to understand the origins and relationships between datasets, crucial for auditing and governance.
- Check Data Quality: Evaluate data quality and ensure data reliability for better decision-making.
- Augment with Business Knowledge: Enrich metadata with relevant business information for consistent understanding across the organisation.
- Organise Data into Domains: Group data into logical domains, streamlining data governance efforts.
This unification brings a unified, simplified, and streamlined experience to discover and govern data effectively. You can now seamlessly search and discover data with relevant business context, organise and govern data based on business domains, and ensure access to trusted data for analytics and data science - all within the same platform: Dataplex.
Final Note
Here is a comparison of Dataplex and some similar data integration services:
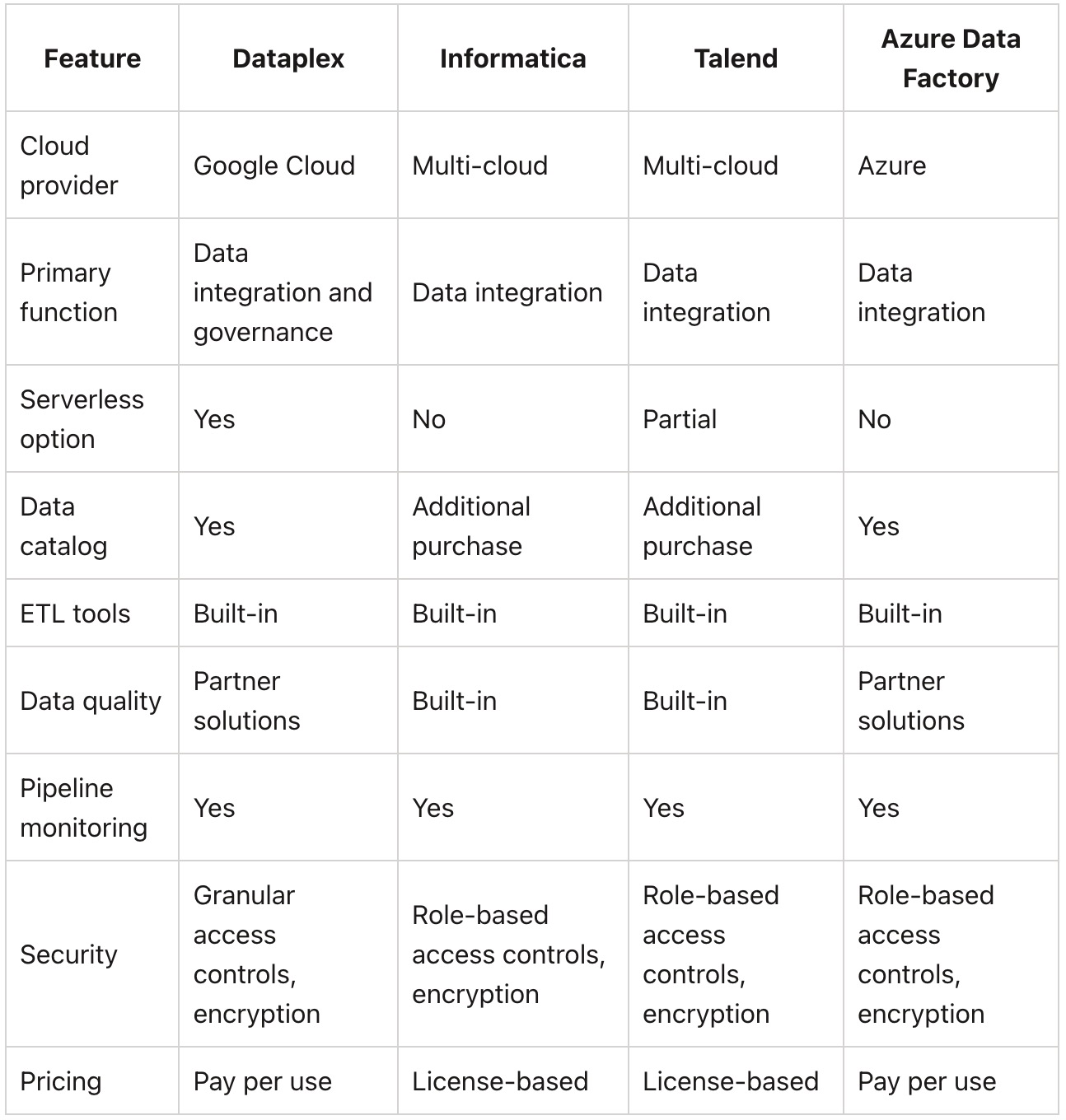
In summary:
Dataplex, Informatica, Talend and Azure Data Factory are all data integration platforms. Unique capabilities include Dataplex's governance, Informatica's data quality, and Talend's partial serverless options. Dataplex is Google Cloud native while the others are multi-cloud or tied to another cloud. Dataplex provides serverless options unlike the others. Overall, Dataplex provides a management plane to control data scattered across clouds. It brings order to complex, distributed data environments through robust metadata, governance and integration capabilities.